
Künstliche Intelligenz (KI) hat sich zu einem zentralen Thema in der Digitalisierung entwickelt. Doch was bedeutet der Einsatz von KI, insbesondere auf embedded Systemen, für Unternehmen und Alltag? Dr. Jan Werth, Lead Data Scientist und Manager Data&AI der Eraneos Analytics GmbH, gibt Einblicke in den Stand der Technik und zeigt, welche Potentiale Spiking Neural Networks und Neuromorphe Prozessoren für die Zukunft bieten.
Künstliche Intelligenz: Grundlagen und Definitionen
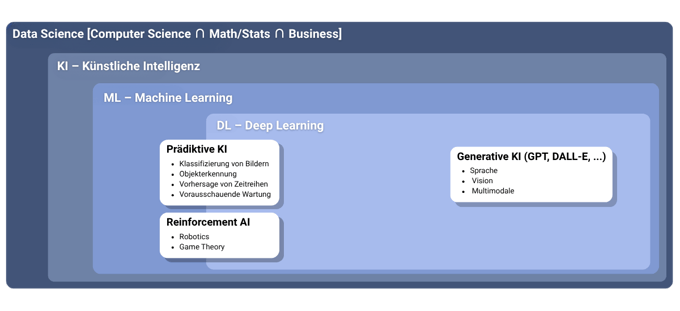
Die Begriffe Data Science, Künstliche Intelligenz (KI), Machine Learning (ML), und Deep Learning (DL) werden oft synonym verwendet, obwohl sie unterschiedliche Blickwinkel darstellen:
- Data Science wird als ein großer Komplex verstanden, der Computer Science, Mathematik/Statistik und Business integriert und auch Audioanalyse sowie Signalverarbeitung umfasst.
- Künstliche Intelligenz ist ein Überbegriff, der maschinelles Lernen beinhaltet.
- Machine Learning ist eine Bezeichnung von Algorithmen, die Probleme lösen und sich in klassisches ML sowie Deep Learning unterteilen.
- Deep Learning ermöglicht die Lösung hochkomplexer Aufgaben, die manuell kaum zu optimieren wären. Innerhalb der KI wird zwischen Prädiktiver KI (z.B. Bildklassifikation, Objekterkennung, Zeitreihenvorhersage), Reinforcement AI (z.B. Robotik, Spieltheorie) und Generativer KI (GenAI) (z.B. GPT, DALL-E für Sprache, Vision, Multimodal) unterschieden.
Herausforderungen und Chancen für den Einsatz von KI
Das Training hochwertiger KI-Modelle erfordert riesige Datenmengen – bei gleichzeitig exponentiellem Wachstum der jährlich generierten Daten. Im Jahr 2024 wurden weltweit rund 147 Zettabytes an Daten generiert. Mit Vorhandensein dieser Datenmengen sinken die Kosten für das Training von KI-Systemen; allein in den vergangenen fünf Jahren sind diese um 99,59 Prozent gesunken. Das fördert den Einsatz von KI in vielen Bereichen des täglichen Lebens, hat aber seinen Preis: der Energieverbrauch von KI-Modellen ist extrem hoch und seit Einführung allgemein verfügbarer Generativer AI enorm gestiegen. Der weltweite Energieverbrauch durch KI-Modelle liegt im Jahr 2024 deutlich über dem der meisten Staaten weltweit. Nur 16 Nationen, darunter die USA und China, verbrauchen mehr Strom als der Einsatz von KI-Modellen. Gleichzeitig ermöglichen nur KI-Modelle die Nutzung großer Datenbestände, die in Unternehmen zu 80 Prozent unstrukturiert vorliegen – in Wikis, Dokumentationen, E-Mails oder Notizen. Erst durch den Einsatz von künstlicher Intelligenz können diese Daten zusammen mit strukturierten Daten – zum Beispiel aus ERP- und CRM-Systemen – genutzt werden.
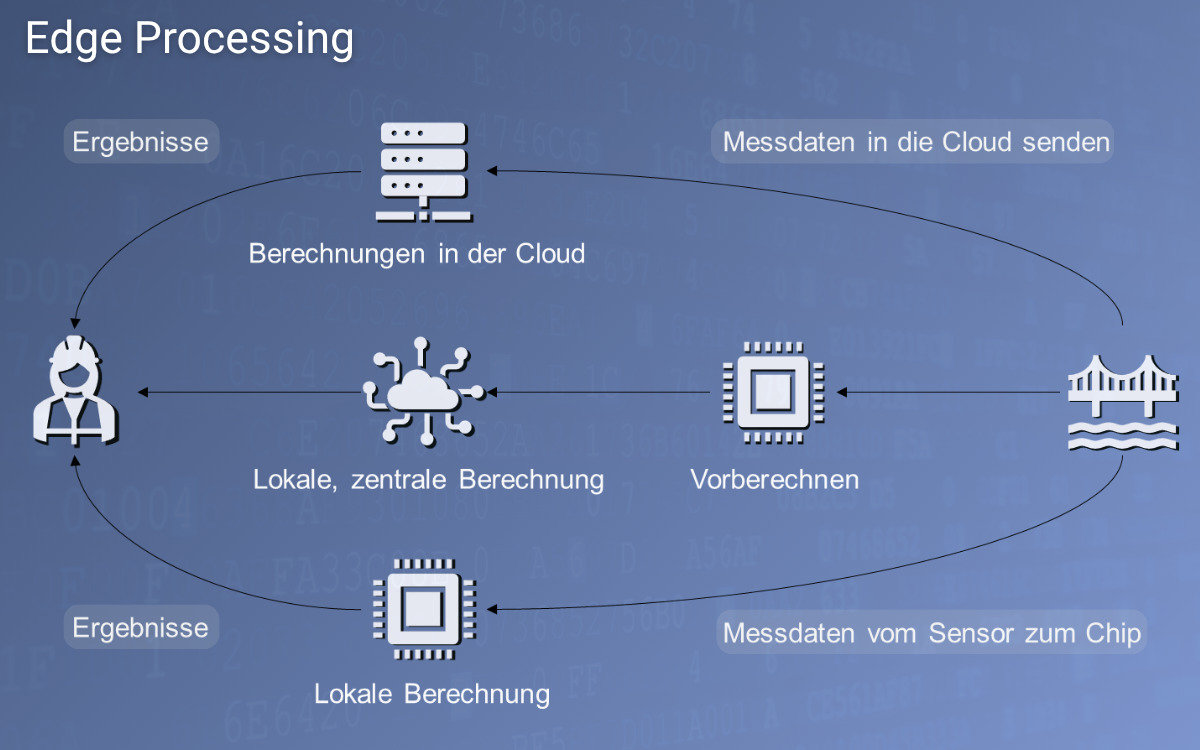
KI-Beschleuniger für Embedded Hardware (Edge Processing)
Edge Processing bezeichnet die lokale Verarbeitung von Daten direkt am Sensor oder in der Nähe des Sensors, anstatt sie zur Berechnung in die Cloud zu senden. Dies reduziert die zu sendende Datenmenge erheblich, was besonders vorteilhaft ist, wenn keine stabile Datenleitung verfügbar ist oder die Bandbreite begrenzt ist. Das Training von KI-Modellen findet in der Regel in der Cloud statt, während die Inferenz, also die Anwendung des trainierten Modells, auf der Embedded Hardware erfolgt.
Für die KI-Berechnung auf Embedded Hardware kommen verschiedene Prozessortypen zum Einsatz:
- CPU (Central Processing Unit): Vielseitig, aber bei der Berechnung von KI-Algorithmen im Vergleich eher langsam, nützlich für kleine Modelle und zur Exploration.
- GPU (Graphics Processing Unit): Optimiert für parallele Verarbeitung, gut geeignet für große Modelle und stationäre Verarbeitung, Modelltraining und Datengenerierung.
- NPU (Neural Processing Unit): Optimiert für Inferenz und Matrixmultiplikation, speziell für KI-Modelle entwickelt und updatebar/austauschbar, ideal für Edge Processing.
- FPGA (Field-Programmable Gate Array): Bietet hohe Leistung für dedizierte, statische Modelle/Berechnungen, ist aber nicht modular und kaum änderbar.
Zahlreiche Anbieter bieten Chips mit KI-Beschleunigern an, die sich in Spitzenleistung (TOPS – Trillion Operations Per Second) und Leistungsaufnahme (Watt) unterscheiden. TOPS ist dabei eine Kennzahl für die Verarbeitungsgeschwindigkeit, aber nicht der einzige entscheidende Faktor. Die Effizienz, gemessen in TOPS pro Watt, ist ebenfalls kritisch für Embedded Hardware.
PHYTEC System on Modules mit KI-Beschleunigern
Für den Einsatz mit KI-Algorithmen bietet PHYTEC eine Reihe von System on Modules an:

Vom KI-Modell zur erfolgreichen Ausführung auf Embedded Hardware
Neben der Rechenleistung spielt auch die Software-Integration eine zentrale Rolle für die Ausführung von KI-Modellen auf Embedded Systemen. Dabei verbindet das Software Development Kit (SDK) des Herstellers verschiedene Bausteine wie Modell-Konverter, die spezielle Modellformate wie TensorFlow Lite, ONNX oder PyTorch verarbeiten können, Bausteine für Modell-Quantisierung & Kalibrierung, die helfen, Informationsverluste auszugleichen sowie Elemente zur Optimierung. Diese beinhalten Techniken wie Graph Rewriting, Operator Fusion, Constant Folding, Dead-Node Pruning, Layout & Datatype Legalisation, Graph Partitioning, Memory-Planning und Liveness Analysis. Ein Scheduler legt die räumliche Zuordnung, zeitliche Anordnung, Tiling-Strategie, Speicherzuweisung und Befehlsstrom-Emission fest, um Paralleloptimierung zu ermöglichen.
Ein gutes SDK, Hersteller-Support, aktive Weiterentwicklung und eine engagierte Community sind entscheidend für eine erfolgreiche Implementierung von KI-Modellen auf einem Embedded System. Zusätzlich müssen klassische Industriethemen wie SIL (Safety Integrity Level), langfristiger Support, Energieverbrauch und Langlebigkeit berücksichtigt werden.
GenAI auf Embedded Hardware
Die Ausführung von Large Language Models (LLMs) – der Grundlage generativer AI – ist auf Embedded Hardware besonders herausfordernd, da LLMs im Vergleich zu Convolutional Neural Networks (CNNs) sehr groß sind und viel VRAM benötigen, der im Embedded-Bereich in der Regel nur begrenzt zur Verfügung steht. Zudem sind NPUs derzeit noch primär auf die Verarbeitung von CNNs ausgerichtet. Nvidia-Chips, obwohl leistungsstark, sind aufgrund ihres hohen Stromverbrauchs und des fehlenden klaren Fokus auf industrielle Anwendungen in erster Linie für Prototyping-Anwendungen geeignet. Eine Alternative für industrieorientierte Ansätze und die Serienproduktion sind Chips von Texas Instruments, die eine Unterstützung für Transformer-Modelle (LLMs) bieten. Gleichzeitig gibt es zahlreiche interessante Ansätze für LLMs, auch bei begrenzten Hardware-Ressourcen und mit niedrigem Energieverbrauch hohe Leistung bieten zu können.
Ein Blick in die Zukunft: Spiking Neural Networks (SNNs) & Neuromorphe Prozessoren
Ein vielversprechendes neues Forschungsfeld sind Spiking Neural Networks (SNNs) und Neuromorphe Prozessoren. SNNs verarbeiten Signale ereignisgesteuert, ähnlich dem menschlichen Gehirn. Sie sind Always-on, aber energieeffizient, da sie keine Dauerverarbeitung benötigen und erst bei Erreichen eines Schwellenwerts (Spike) aktiv werden. Dies ermöglicht eine Filterfunktion und ist energiesparend sowie echtzeitfähig für schnelle Reaktionen. Neuromorphe Prozessoren sind speziell für solche SNNs optimiert und ermöglichen das On-Chip Learning. Im Gegensatz zu fixen neuronalen Netzen können sich die Gewichtungsfaktoren der Neuronen auf diesen Chips kontinuierlich verändern, basierend auf eingehenden Signalen. Dies ermöglicht es dem Modell, sich an aktive Umgebungen anzupassen, was besonders für Robotik-Anwendungen relevant ist.
Erste kommerzielle Entwicklungen in diesem Bereich werden von Intel vorangetrieben. Zudem entwickelt das französische Unternehmen Prophesee aktuell Event-based Vision Sensoren für Industrie, Automotive und Forschung. Diese Sensoren reduzieren Datenmengen enorm, indem nur relevante Pixeländerungen (Events) ausgewertet werden, was extrem schnelle Reaktionszeiten ermöglicht. Erste Kamera-Module des Unternehmens sind bereits verfügbar. Ein weiteres Beispiel für aktuelle Entwicklungen is BrainChip Holdings Ltd. Das Unternehmen aus Australien entwickelt neuromorphe Prozessoren mit vollständig digitalem, ereignisbasiertem Design. Ihre Akida AKD1000 SoC und Akida Pico Co-Prozessor unterstützen inkrementelles On-Chip-Lernen, reduzieren die Cloud-Abhängigkeit und haben einen extrem niedrigen Stromverbrauch von weniger als 1 mW. M.2- & PCIe-Module sind für Entwickler und OEMs erhältlich und kosten zwischen 250 und 500 US-Dollar. Generell ist die Entwicklung im Bereich Embedded AI stark vorangeschritten – und entwickelt sich fast täglich weiter. Die Auswahl der richtigen Hardware und die Berücksichtigung des gesamten Ökosystems (Software-Support, Community) sind entscheidend für den Erfolg von Projekten.
Generell ist die Entwicklung im Bereich Embedded AI stark vorangeschritten – und entwickelt sich fast täglich weiter. Die Auswahl der richtigen Hardware und die Berücksichtigung des gesamten Ökosystems (Software-Support, Community) sind entscheidend für den Erfolg von Projekten.
Mit PHYTEC und eraneos zum erfolgreichen Embedded AI Projekt
Sie suchen den passenden Prozessor für Ihr Embedded System und KI-Anwendungen oder Expertise für die erfolgreiche Umsetzung? PHYTEC bietet für den Einsatz mit klassischen Algorithmen, Machine Learning und Künstliche Intelligenz optimierte System on Modules sowie darauf basierende Produkte für den industriellen Serieneinsatz. In Zusammenarbeit mit Partnern wie eraneos beraten wir Sie von der Produktidee bis zum Serienerfolg und Unterstützen Sie im gesamten Lebenszyklus Ihrer Anwendung.